

Modern applications are often built with tens of thousands — sometimes even tens of millions — lines of code. As a result, it’s simply not practical for most organizations to use manual processes to identify dependencies (and the dependencies of those dependencies, and so on). However, without an accurate inventory of your dependencies, it’s nearly impossible to understand and manage open source license compliance obligations and security risks.
That’s why code scanning tools like FOSSA now play an integral role in software development. These tools automate dependency identification, giving engineering teams at-a-glance insight into dependencies and their metadata.
But the mechanics of code scanning vary depending on the programming language being analyzed. In this blog, we’ll explain why scanning C and C++ code is particularly challenging, discuss common methods of dependency inclusion, and share how FOSSA is working to address challenges scanning C/C++ code.
This piece is based on a webinar we recently hosted: Challenges in Scanning C/C++ Code for Dependencies. If you’re interested in this topic and would like more information, we’d recommend you view the on-demand version, which is linked below.
Why Scanning C and C++ Code is Difficult
Scanning code written in unmanaged languages like C and C++ code is different — and can be more difficult — than scanning code written in managed languages. There are several reasons why this is the case. The biggest is that managed languages have manifest files. For example, you’d often have a Cargo manifest for a Rust project, where the Cargo manifest contains different dependencies and different versions of dependencies. Code scanning tools are able to examine that manifest to develop a ground floor of understanding for that project.
C and C++ largely don’t have manifests like this. Some package managers exist, such as Conan, but they don’t seem to be an ecosystem-wide standard. For example, a Rust project without Cargo is extremely rare, but a C/C++ without Conan is the norm. Given that, we have to turn to some other strategies that aren’t primarily looking at a manifest file.
Methods for C and C++ Dependency Inclusion
Before we get into the specific ways FOSSA identifies dependencies in C and C++ code, let’s spend a moment discussing how dependencies are included in C and C++ projects in the first place. There are three main methods programmers use to do this: vendoring code, static linking, and dynamic linking.
- Vendored Code
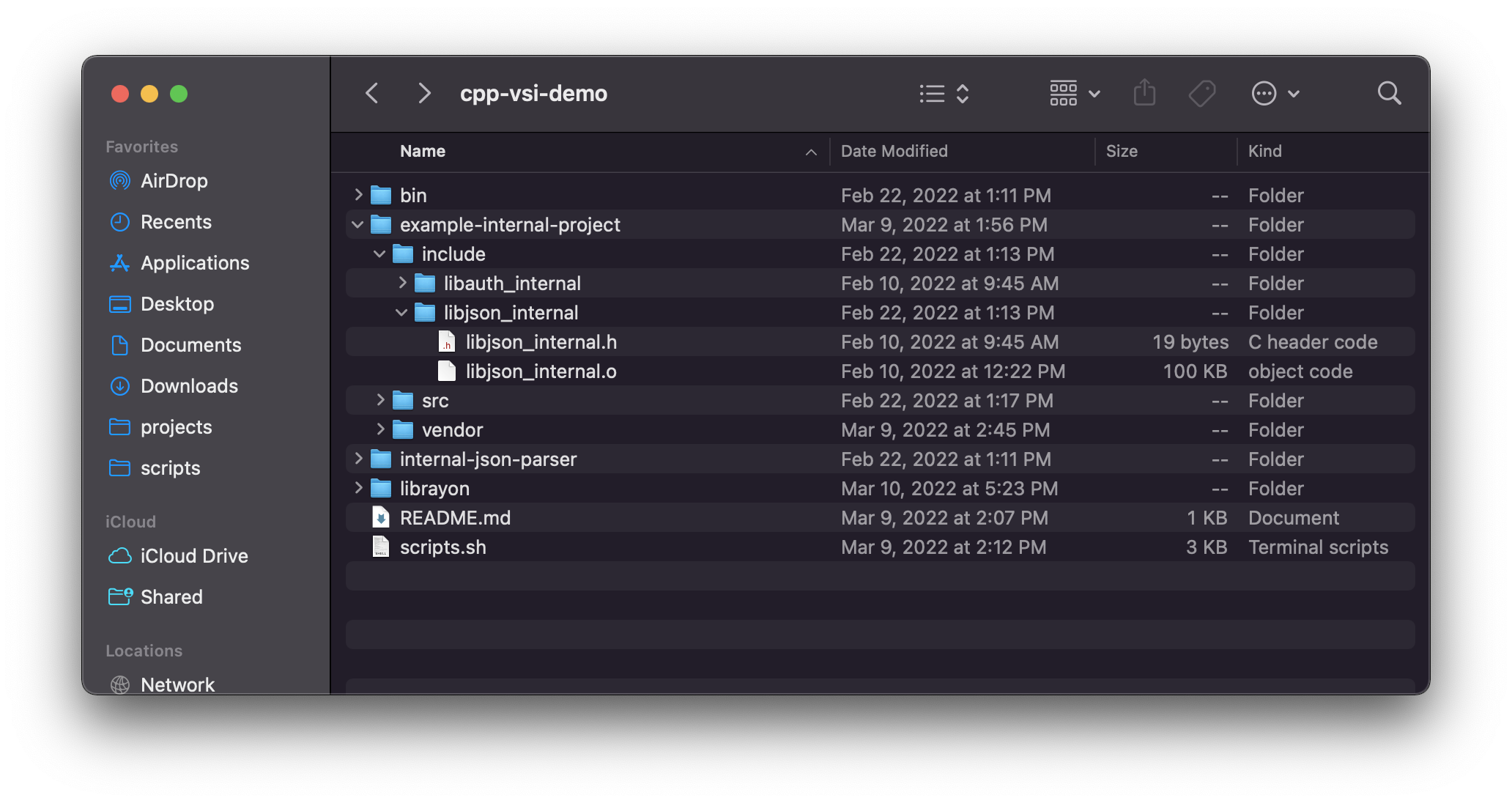
The screenshot below is an example of a vendor folder inside a project. This folder contains open source projects which are included in a more or less wholesale manner. Typically, the dependencies that are put in a vendor or similar folder will be some subset of the open source project, sometimes with slight modifications.
Developers in this kind of scenario will consider that vendored library to be part of their first-party project. So, whenever they build their first-party project, their build script will also build these third-party dependencies, and it’s basically all the same to the C compiler.
The only way we typically know those open source dependencies are dependencies at all is just because they’re in the vendor folder, though different organizations and projects have different conventions for how to manage those dependencies — they’re not always inside the vendor folder. But there is always some way of storing them inside the project tree and building them into the project.
2. Static Linking
In the vendoring scenario, it can be relatively easy to pull in dependencies. But, sometimes we don’t want to pull in a whole dependency file tree. For example, perhaps an internal team is building an open source project and distributing it to other teams in the organization. In that case, instead of distributing all the source code, it might be easier or otherwise more desirable to distribute the binary and its associated headers.
Typically, these statically linked binaries are also stored inside of the project directory. Sometimes they can be statically linked from the operating system package manager, but often we’ve seen them inside the actual directory tree itself.
3. Dynamic Linking
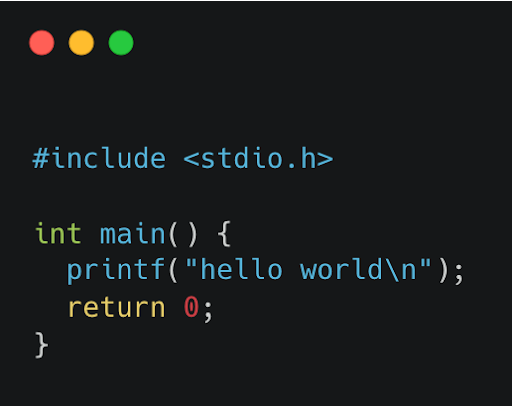
From what we’ve seen, this is the most popular way of including dependencies in C and C++ projects. The screenshot below is a code example where we’re including the C standard IO library stdio.h — this is almost always dynamically linked depending on how you build your application.
Dynamic linking is where we use pre-built dependencies that are typically provided by the operating system package manager, and the application loader links them into the first-party application at run time. It all just comes together, and you don’t have to distribute these binaries yourself. Dependencies included this way can be almost invisible unless you have explicit support for the build tooling or inspecting the output binary.
How FOSSA Identifies Dependencies in C and C++ Projects
Now that we’ve talked about the three pillars for dependency inclusion in C/C++ projects, we’ll shift our focus to how FOSSA’s software composition analysis handles each situation.
- Vendored Code
FOSSA has developed a proprietary technology to identify dependencies introduced in vendored code. It essentially works by comparing the fingerprints of files inside your project with the open source projects that we have seen before. Now, sometimes these vendored libraries will be slightly modified from the original open source library. You might have added to the project, or only included a subset of the project. So, our algorithm attempts to match those partial projects as well. And, essentially, the more of it we can match, the more confident we are that we’re picking the right thing. Ultimately, this process produces a statistically likely match.
2. Static Linking
When we talk about dependencies introduced via static linking, we’re referring to a situation along the lines of when an organization passes around a compiled binary that’s built for a specific target.
Let’s say, for example, you download Facebook’s folly library, compile it, and want to share the resulting statically compiled library internally.
You will have compiled it for a specific architecture, so it can be difficult to look at that compiled binary and match it to an open source project FOSSA’s scanner previously scanned. This is because of the varied nature of the available compiler targets.
Our current approach is whenever an internal team builds a project, they tell the FOSSA service about it. When we scan a downstream project that contains that built library, the downstream project is able to identify that library that we’ve been told about before. It’s important to note, though, that we are still building out our code scanning technology to improve detection of C/C++ dependencies introduced via static linking; we look forward to sharing updates in the months ahead.
3. Dynamic Linking
For dependencies included via dynamic linking, we wait for the project to be built. When you run your project through the FOSSA CLI, you also provide a location for the resulting binary that is the output of that project. We then inspect that project for dynamically linked libraries.
Our strategies for doing that are varied. Today, it comes down to running LDD on that binary, which enables us to find out what libraries are included at load time. Once we have that list of libraries, we can then go to the operating system package manager and say, “I’ve got this binary, which library owns it?”
In the event where no library brought that binary in — for example, you manually placed it on the system yourself — we fall back to showing it in as an unmanaged, dynamically linked dependency. From there, you have several options to manage that dependency in our product’s UI.
Overcoming Challenges Scanning C and C++ Code
Given the amount of code in modern software applications, scanning has become a mission-critical part of identifying dependencies — which is the starting point for managing vulnerabilities and ensuring compliance with open source licenses. But, scanning C and C++ code is more challenging than scanning code written in managed programming languages for the reasons we’ve discussed in this piece.
For more information on our approach to code scanning — or if your organization is interested in trying our C/C++ code scanning solutions — please get in touch with our team.
